Problem description
In developing database systems, generating IDs is a crucial task. IDs ensure the uniqueness of data, facilitate queries, and establish relationship constraints in databases. Most modern database management systems (DBMS) can generate auto-increment IDs. We can delegate this task to the DBMS entirely and not worry about the uniqueness. However, there are several reasons why we shouldn’t use auto-increment IDs, especially for distributed systems. The most important reason is that in distributed systems with independent servers, using per-server auto-increment IDs does not guarantee uniqueness and can lead to duplication problems.
Snowflake ID is the solution developed by Twitter engineers to address this problem. According to statistics, about 6,000 tweets are written and posted on Twitter every second. How can we generate 6,000 IDs per second independently on multiple servers without collision?
Hold on! What about UUID?
UUID is also a widely used ID generation technique that has been used in software for a long time.
The idea of this technique is to use a 128-bit number as an ID. A 128-bit integer means that if we use 6,000 IDs every second, it will take over 2^128 / (6000 * 3600 * 24 * 365) = 1.79838*10^27 (how is it pronounced, octillion?) to exhaust them. And if we randomly pick 103 trillion of 126-bit numbers, the chance of a collision is one in a billion. Of course, this number is not generated in a simple incremental count like 1, 2, 3, … but follows a certain standard. And when generated accordingly, UUIDs can solve the problem of generating non-duplicate IDs in distributed systems.
But it introduces another problem. 128-bits is unnecessarily large. And most computers don’t support us working directly with the 128-bit integer data type. So we usually have to use strings to process them. In addition, a large-size ID hurts the query performance because the index gets larger and operations/calculations become more costly.
Example UUIDs:
8fbb69e1-2132-4c86-911b-4cc182a5513a
b1f352c3-2126-4cca-9eec-349cdb69b611
6c7fa5c6-1b70-4b47-8690-760f2871943d
df495b1b-cd86-4e08-a42a-9f73d2c5afd1
13e1b2c2-ed6e-46ee-94a3-efce635ef268
Snowflake ID
To solve this problem, Twitter engineers introduced a system called Snowflake ID. The idea of this system is to programmatically generate a 64-bit integer to represent the ID. But how does each server independently generate this ID without collision?
The proposed method is as follows:
- The first 1 bit is not in use (always 0) to make it fit into a signed integer (always positive).
- The next 41 bits store information about the ID creation time, measured in milliseconds from a given point in time (epoch 1288834974657 in Unix time).
- The next 10 bits store information about the machine requesting the ID.
- The last 12 bits are a sequential counter from 1 to 4096. To avoid duplicate IDs within the same time frame on the same machine.
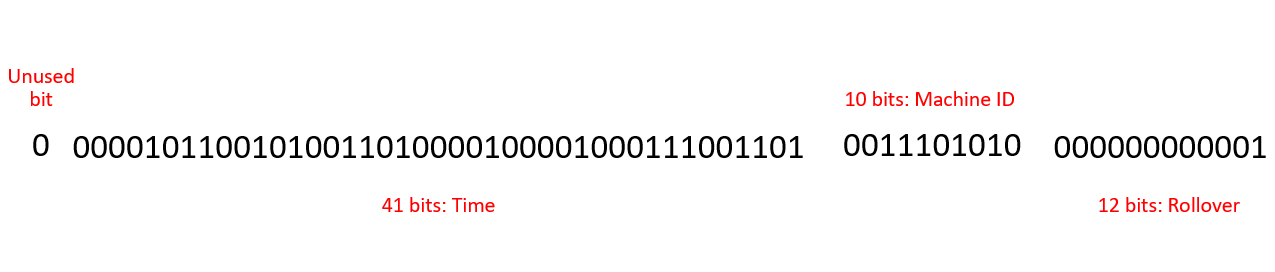
The only scenario where collisions can occur is when a single machine requests more than 4096 IDs in a single millisecond (or in the case of Twitter, when a machine posts 4096 tweets in a millisecond). With Snowflake ID, we are able to solve the problem of generating non-duplicate IDs in distributed systems with a 64-bit integer. Additionally, Snowflake ID itself contains information about the creation time. Therefore, we can know the creation time of an ID just by looking at the ID, or we can sort by ID and get results sorted by time.
Conclusion
Is Snowflake ID the answer for every system? Absolutely not! Nothing is the answer for everything. Besides the ID generation strategies mentioned above, there are many other approaches (e.g. Flickr’s centralized ticket server). There are always many ways to solve a problem. Each goes with pros and cons. Don’t limit yourself to existing methods; always look for new, context-appropriate solutions.