Introduction
Apache Spark is a powerful open source distributed computing engine designed to handle large datasets across clusters. PySpark is the Python programming API for Spark. It allows data engineers and data scientists can easily utilize the framework in their preferred language.
This post is a continuation of the previous tutorial. Originally a Jupyter notebook I created while learning PySpark, I recently found it and decided to update it and publish it on my blog.
UDFs (user-defined functions) are an integral part of PySpark, allowing users to extend the capabilities of Spark by creating their own custom functions. This article will provide a comprehensive guide to PySpark UDFs with examples.
Understanding PySpark UDFs
PySpark UDFs are user-defined functions written in Python code. We create functions in Python and register them with Spark as UDFs. They enable the execution of complicated custom logic on Spark DataFrames and SQL expressions.
However, note that UDFs are expensive. We should always prefer built-in functions whenever possible. PySpark comes with a number of predefined common functions, and many more new functions are added with each new release.
In summary, with PySpark UDFs, what goes in is a regular Python function, and what goes out is a function to work on the PySpark engine.
Creating an UDF
All of the following examples are a continuation of the previous article. You can find an executable notebook containing both articles here.
Below is an example of a “complicated” decision tree function that classifies transactions:
# PySpark UDFs example
def classify_tier(amount:float) -> int:
if amount < 500:
return 0
if amount < 10000:
return 1
if amount < 100000:
return 2
if amount < 1000000:
return 3
return 4
It is a regular Python function that receive a float and return an int. We have to make it a PySpark UDF before actually using it.
from pyspark.sql import functions as F
# pyspark.sql.functions provides a udf() function to promote a regular function to be UDF.
# The function takes two parameters: the function you want to promote, and the return type of the generated UDF
# The function return a UDF
classifyTier = F.udf(classify_tier, T.ByteType())
Then we can use it like any other PySpark function.
df.select('nameOrig', classifyTier(df.amount).alias('tier')).orderBy('tier', ascending=False).show(10)
+-----------+----+
| nameOrig|tier|
+-----------+----+
|C1495608502| 4|
|C1321115948| 4|
| C476579021| 4|
|C1520267010| 4|
| C106297322| 4|
|C1464177809| 4|
| C355885103| 4|
|C1057507014| 4|
|C1419332030| 4|
|C2007599722| 4|
+-----------+----+
The pyspark.sql.functions.udf() function can also be used as a decorator which produce the same result.
# pyspark udf decorator example
# Note that classifyTier is a UDF, not a regular function anymore.
@F.udf(T.ByteType())
def classifyTier(amount:float) -> int:
if amount < 500:
return 0
if amount < 10000:
return 1
if amount < 100000:
return 2
if amount < 1000000:
return 3
return 4
If you want to use it in a Spark SQL expression, we need to register it first.
# Register the regular Python function with spark.udf.register
spark.udf.register('classifyTier', classify_tier)
spark.sql('''
SELECT nameOrig, classifyTier(amount) tier
FROM df
ORDER BY tier DESC
''').show(10)
+-----------+----+
| nameOrig|tier|
+-----------+----+
| C263860433| 4|
| C306269750| 4|
|C1611915976| 4|
|C1387188921| 4|
| C300262358| 4|
| C389879985| 4|
|C1907016309| 4|
|C1046638041| 4|
|C1543404166| 4|
|C1155108056| 4|
+-----------+----+
Simple enough? Write a Python function, make it a UDF, use it. But it is not the most interesting part.
Pandas UDF
With Python UDFs, PySpark will unpack each value, perform the calculation, and then return the value for each record. A Pandas UDF is a user-defined function that works with data using Pandas for manipulation and Apache Arrow for data transfer. It is also called a vectorized UDF. Compared to row-at-a-time Python UDFs, pandas UDFs enable vectorized operations that can improve performance by up to 100x.
Series to Series UDF
These UDFs operate on Pandas Series and return a Pandas Series as output. When Spark runs a Pandas UDF, it divides the columns into batches, calls the function on a subset of the data for each batch, and then concatenates the output. It is preferable to use a Pandas Series-to-Series UDF if possible, instead of using a regular Python UDF. We use pyspark.sql.functions.pandas_udf to create a Pandas UDF.
import pandas as pd
# You can also promote the function to PySpark Pandas UDF as getUserType = F.pandas_udf(get_user_type, T.StringType())
# Each User ID starts with a letter represent its type
@F.pandas_udf(T.StringType())
def getUserType(name: pd.Series) -> pd.Series:
return name.str[0]
The only difference in syntax is that the Python function now takes a pandas.Series' and returns a pandas.Series’. And then we can use it as a Spark function.
(
df.select(getUserType(df.nameDest).alias('userTypeDest'), df.amount)
.groupBy('userTypeDest')
.agg(
F.mean('amount').alias('avgAmount'),
F.count('*').alias('n')
)
.orderBy('avgAmount', ascending=False)
.show(10)
)
+------------+------------------+-------+
|userTypeDest| avgAmount| n|
+------------+------------------+-------+
| C| 265083.4571810173|4211125|
| M|13057.604660187604|2151495|
+------------+------------------+-------+
Iterator of Series to Iterator of Series
Due to the distributed nature of Spark, the entire series is not fed into the UDF at once; instead, each cluster calls the UDF on its own batch of data and then aggregates the result. PySpark Iterator of Series to Iterator of Series UDFs are very useful when we have an time-consuming cold start operation (e.g. initialize a machine learning model, check for some server statuses,…) that you need to perform once at the beginning of the processing step.
from time import sleep
from typing import Iterator, Tuple
@F.pandas_udf(T.ByteType())
def getNameIdLength(name: Iterator[pd.Series]) -> Iterator[pd.Series]:
# Heavy task
# sleep(5)
# name is a Iterator
# name_batch is a pd.Series
for name_batch in name:
name_len = name_batch.str.len()
name_len[~name_batch.str[0].str.isnumeric()] -= 1
# yield because we return an iterator
yield name_len
(
df.select(getNameIdLength(df.nameOrig).alias('idLen'), 'amount')
.groupBy('idLen')
.agg(F.mean('amount').alias('avgAmount'))
.orderBy('avgAmount')
.show(10)
)
+-----+------------------+
|idLen| avgAmount|
+-----+------------------+
| 4|155070.73742857145|
| 7|177477.50726081585|
| 10| 179702.4408980949|
| 9|179898.05510125632|
| 8| 181572.2097899971|
| 6|197756.81529433408|
| 5|199594.79368029739|
+-----+------------------+
Iterator of multiple Series to Iterator of Series UDF
Iterator of Multiple Series to Iterator of Series UDF has the same characteristics as Iterator of Series to Iterator of Series UDF. The difference is that the underlying Python function receives an iterator for a tuple of Pandas Series.
def amount_mismatch(values: Iterator[Tuple[pd.Series, pd.Series, pd.Series, pd.Series]]) -> Iterator[pd.Series]:
# Heavy task
# ...
for oldOrig, newOrig, oldDest, newDest in values:
yield abs(abs(newOrig - oldOrig) - abs(newDest - oldDest))
# Create an UDF. You can also use decorator.
amountMismatch = F.pandas_udf(amount_mismatch, T.DoubleType())
(
df.select(
df.type,
amountMismatch(df.oldBalanceOrig, df.newBalanceOrig, df.oldBalanceDest, df.newBalanceDest).alias('mismatch')
)
.groupBy('type')
.agg(
F.mean('mismatch').alias('avgMismatch')
)
.orderBy('avgMismatch', ascending=False)
.show(10)
)
+--------+------------------+
| type| avgMismatch|
+--------+------------------+
|TRANSFER| 968056.4538892006|
|CASH_OUT|170539.39652580014|
| CASH_IN| 50038.95466155722|
| DEBIT| 25567.53969902471|
| PAYMENT| 6378.936662041953|
+--------+------------------+
Group aggregate UDF
Group aggregate UDF, also known as the Series to Scalar UDF, reduces the input pandas.Series into a single value.
@F.pandas_udf(T.DoubleType())
def getStdDeviation(series: pd.Series) -> float:
# Use built-in pandas.Series.std
return series.std()
(
df.groupBy('type')
.agg(
getStdDeviation(df.amount).alias('var')
)
.orderBy('var', ascending=False)
.show(10)
)
+--------+------------------+
| type| var|
+--------+------------------+
|TRANSFER|1879573.5289080725|
|CASH_OUT|175329.74448347004|
| CASH_IN|126508.25527180695|
| DEBIT|13318.535518284714|
| PAYMENT|12556.450185716356|
+--------+------------------+
Group map UDF
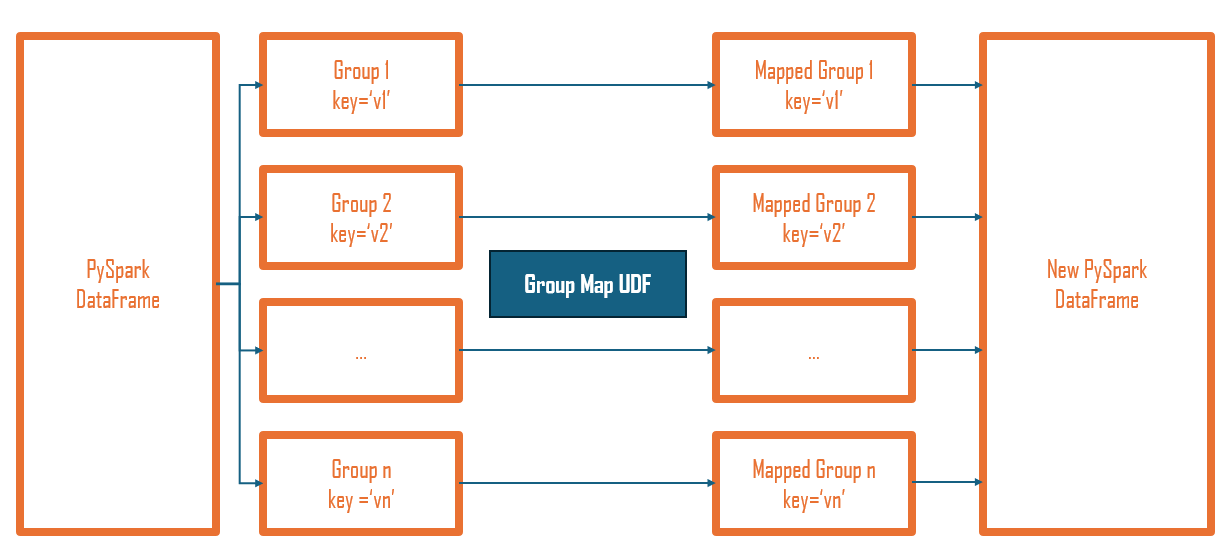
As with the Group Aggregate UDF, we use groupBy() to divide a Spark DataFrame into manageable batches. Each input batch is mapped over by the Group Map UDF, resulting in a (Pandas) DataFrame, which is then combined back into a single (Spark) DataFrame.
def normalize_by_type(data: pd.DataFrame) -> pd.DataFrame:
result = data[['type', 'amount']].copy()
maxVal = result['amount'].max()
minVal = result['amount'].min()
if maxVal == minVal:
result['amountNorm'] = 0.5
else:
result['amountNorm'] = (result['amount'] - minVal) / (maxVal - minVal)
return result
# We can use the SQL string-based schema like below comment
# schema = 'type string, amount double, amountNorm double'
schema = T.StructType([
T.StructField('type', T.StringType()),
T.StructField('amount', T.DoubleType()),
T.StructField('amountNorm', T.DoubleType())
])
(
df.groupBy('type')
.applyInPandas(normalize_by_type, schema)
.show(10)
)
+--------+---------+--------------------+
| type| amount| amountNorm|
+--------+---------+--------------------+
|TRANSFER| 181.0|1.929785364412691...|
|TRANSFER| 215310.3| 0.00232902269229461|
|TRANSFER|311685.89|0.003371535041334062|
|TRANSFER| 62610.8|6.772443276469881E-4|
|TRANSFER| 42712.39|4.619995945019032E-4|
|TRANSFER| 77957.68|8.432543299642404E-4|
|TRANSFER| 17231.46|1.863677235062513...|
|TRANSFER| 78766.03|8.519983994671721E-4|
|TRANSFER|224606.64|0.002429582898990...|
|TRANSFER|125872.53|0.001361558008596...|
+--------+---------+--------------------+
only showing top 10 rows
You can see that in the example above, we don’t need to explicitly create a UDF. This is due to the use of applyInPandas function which is new in PySpark 3.0.0. The function takes a regular Python function and a result schema as parameters. If you want to create a Group Map UDF, you can refer to the following code:
# It is preferred to use 'applyInPandas' over this API (in Spark 3).
# This API will be deprecated in the future releases.
# As it will be deprecated soon, type hint inference is not supported. So, we have to specify PandasUDFType explicitly
NormalizeByType = F.pandas_udf(normalize_by_type, schema, F.PandasUDFType.GROUPED_MAP)
(
df.groupBy('type')
.apply(NormalizeByType)
.show(10)
)
+--------+---------+--------------------+
| type| amount| amountNorm|
+--------+---------+--------------------+
|TRANSFER| 181.0|1.929785364412691...|
|TRANSFER| 215310.3| 0.00232902269229461|
|TRANSFER|311685.89|0.003371535041334062|
|TRANSFER| 62610.8|6.772443276469881E-4|
|TRANSFER| 42712.39|4.619995945019032E-4|
|TRANSFER| 77957.68|8.432543299642404E-4|
|TRANSFER| 17231.46|1.863677235062513...|
|TRANSFER| 78766.03|8.519983994671721E-4|
|TRANSFER|224606.64|0.002429582898990...|
|TRANSFER|125872.53|0.001361558008596...|
+--------+---------+--------------------+
only showing top 10 rows
When executes Group Map UDF, Spark will:
- Split the data into groups using
groupBy. - Apply the function to each group.
- Combine the results in a new PySpark
DataFrame.
Conclusion
In summary, PySpark UDFs are an effective way to bring the power and flexibility of Python to Spark workloads. When used properly, they can help extend Spark’s capabilities to solve complex data engineering challenges. Together with the previous tutorial, you can now cover most data manipulation and analysis tasks. Happy coding!