During a recent technical meeting, one of my colleagues raised a concern about two concurrent inserts for the same object from different processes hitting the system at once. After explaining this to him, I realized that even among experienced engineers, the inner workings of the database are often treated as a black box. There is a persistent uncertainty about what the database guarantees and what it leaves up to developers.
Problem Statement
User Registration Flow
To understand the concurrent inserts problem, the most common example is the user registration flow. When a user reaches our system, they first select a username. The system must guarantee that this username belongs to one and only one person.
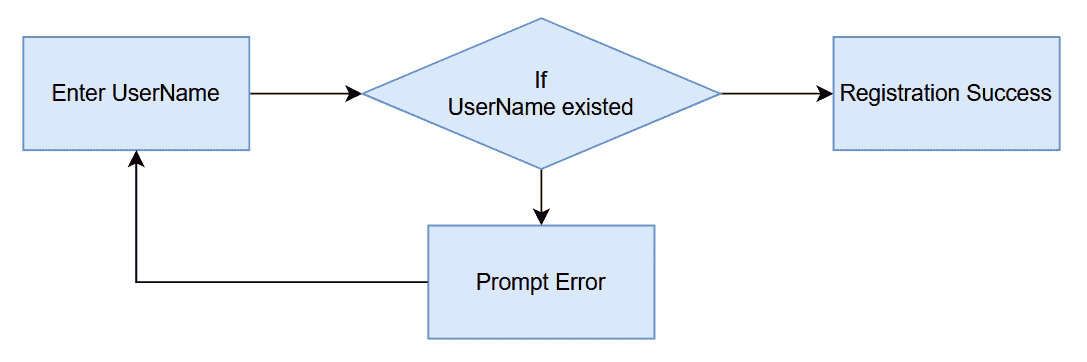
Check-Then-Act
After you see the requirement, you sit down to code immediately. You simply follow a linear logical path. You first check if the username exists in the database. If the username exists, you throw an error to users. Otherwise, you insert a new user record to the database. So, you just implemented what is known as the Check-Then-Act pattern. The code usually looks like this:
# Pseudo Python code
def register(username):
# Step 1: The Check
# We query the database to see if the username is already claimed.
existing_user = db.execute("SELECT id FROM users WHERE username = %s", (username,))
if not existing_user:
# Step 2: The Act
# If the result is empty, we assume the coast is clear and perform the write.
db.execute("INSERT INTO users (username) VALUES (%s)", (username,))
return "Registration successful."
else:
return "Error: Username already exists."
This pattern is incredibly common because it is intuitive. It is how we think and act in real life. We check if a parking spot is empty before we pull the car in. It is how we are taught to code at school. And it looks the same as the received requirements.
The Race Condition
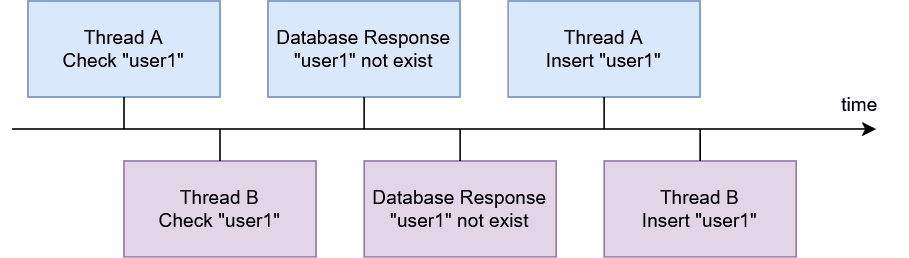
The fatal flaw in “Check-Then-Act” is the tiny window of time between the “Check” and the “Act”. Imagine that two users, Alice and Bob, both try to claim the username “user1” at the same exact millisecond.
- Thread A (Alice) checks the database and sees that “user1” is available.
- Thread B (Bob) also checks the database, but a fraction of a second before Thread A commits its write. Thread B also sees that “user1” is available.
- Both threads then proceed to Insert.
You now have two rows in your table with the username “user1”. Your authentication and authorization logic could be broken.
The “Check-Then-Act” pattern is even more fragile in a production environment because a single database can hardly handle massive real-world loads. For this reason, we often distribute the load across multiple databases. In the simplest setup, all writes are routed to a leader database, and all reads are distributed among replicas. It means that the “Check” may interact with one database while the “Act” is performed on another. And the replication lag between these databases makes the race condition more likely to happen.
How to INSERT?
To find the solution, we first need to understand one important aspect of INSERT. When inserting data, we usually provide values for all columns except the primary key. We often rely on databases to generate an auto-increment value for us. Two update statements could possibly block if they interact with the same primary key. But two insert statements would never do so because they always use different primary keys. Therefore, two concurrent inserts always succeed and will cause duplication.
The above behavior gives us an insightful clue. No matter how many concurrent inserts hit your database, it guarantees that every new row gets a distinct ID. And the fact that the database assign IDs in auto-increment order (e.g., 1, 2, 3, 4, 5, etc.) tells us it has a mechanism to process these IDs sequentially, even if insert requests may arrive at the same time.
Unique Constraint
The problem is not the database cannot handle simultaneous inserts. The problem is we must tell the database that usernames require the same strict treatment as IDs. And we can solve this by simply adding a UNIQUE constraint to the username column.
Thanks to the unique constraint, duplication is no longer a concern. The database will ensure that, at any given time, no two users share the same username.
Just INSERT
Once the UNIQUE constraint has been set up, you can insert data without hesitation. We no longer need existence checks beforehand. We abandon the “Check-Then-Act” pattern entirely. We just insert.
# Pseudo Python code
def register(username):
try:
# Just try to insert.
# The database is the only one who knows the truth.
db.execute("INSERT INTO users (username) VALUES (%s)", (username,))
return "Success"
except UniqueViolationError:
# The database rejected us.
# This is a valid business logic outcome, not a system crash.
return "Error: Username already exists."
Databases will handle our concurrent inserts as if they were executed sequentially. So, Alice and Bob both try to register the username “user1.” Their requests arrive at the same time. One request will be executed first and succeed. The other will wait, then violate the unique constraint and fail. We will catch that failure and prompt the user to choose another username.
Multi-Leader
The “Just Insert” approach is clean. It works perfectly in a single-leader setup. So, we ship it and life is good.
Then, the product grows.
Why Multi-Leader?
A single leader database can only handle a certain number of writes per second. When users register, post, and update their profiles all at once, the database becomes the bottleneck. You also start thinking about geography. A user in Tokyo shouldn’t have to wait for a round trip to a server in London just to register. Latency adds up. Users leave.
So, you scale out. Promote multiple nodes to accept writes. Each region has its own leader database that accepts writes. Writes go to the nearest database. Then, the leaders synchronize with each other in the background. This is called multi-leader replication.
Reads are fast. Writes are fast. Everything feels great. Until you think about usernames again.
Why UNIQUE not work?
The UNIQUE guarantee is only valid where there is one database. In a multi-leader setup, Leader A in Tokyo and Leader B in London are both accepting writes independently. They do not talk to each other before committing. Alice registers “user1” on Leader A. Bob registers “user1” on Leader B. Both leaders check their own local data. Both see no conflict. Both succeed. Both return a success response to their respective users.
Now both leaders have a row for “user1”. The UNIQUE constraint on each node was never violated locally. The violation only becomes visible after the leaders then sync with each other.
Solutions
There is no magic answer here. Every solution is a trade-off between consistency, availability, and difficulty. You have to pick one that works best for you.
The simplest method is optimistic conflict resolution. You allow conflict. No locks. No coordination. No waiting. Every INSERT request succeeds instantly. And you change business requirement to resolve conflicts.
The most common strategy is Last-Write-Win. For the user registration problem, you might want to use First-Write-Win. The idea is simple, you keep one and discard others. You can also keep all, but with additional discriminators to enforce uniqueness. Discord used to take this approach. They appended a 4-digit numeric discriminator to every username. So that, in theory, they allowed 10,000 users sharing the username “user1”, ranging from “user1#0000” to “user1#9999”.
The fundamental problem with this approach is the user experience. In most cases, such as when a user updates their profile image from both their laptop and phone at the same time, it is safe to keep the latest one. However, this is not as easy with uniqueness-sensitive data, such as usernames. You definitely do not want to tell a user that they have successfully taken a username. Then, when they log in the next time, you have to apologize because you found out that someone had taken that name before them. Even the discriminator is also a poor user experience. No one remembers a random number associated with their name. Discord has finally decided to move away from that approach.
Another method is to stop fighting the problem of multi-leader setup and route uniqueness-sensitive data to a dedicated service backed by a single-leader database. So, you can keep everything else in the multi-leader system for performance, but send user registration to the single-leader database. Your main database stays distributed and fast. Only the username is centralized, because it is the only part that genuinely needs to be.
Final Thoughts
The moment you start treating the database as a partner rather than a black box, a lot of problems either disappear entirely or become much easier to reason about. You stop being surprised by behaviors that are actually well-documented. You start asking better questions. Understanding your tools in depth is especially important in the era of AI. AI can provide you code that looks correct. But the decision of whether that code is actually correct is still yours.